
Willem van Peursen, Martijn Naaijer, Constantijn Sikkel, Mathias Coeckelbergs
Encoded text as strings
In our previous blogpost, we explained how the ETCBC morphological encoding results in a concisely structured string. We concluded that blogpost by observing that this string contains the letters of the Hebrew phrase in transliterated format and that the encodings are added in-line, rather than as flags or footnotes and that this means that the process of the linguistic encoding can be conceptualized as the transformation of one string into another. In this blogpost we will elaborate on this and explain how this helped us apply sequence-to-sequence (seq2seq) models for the morphological parsing of inflectional languages.
The input string for the morphological parsing is the raw text, which, in the example that we gave in Part I of this blogpost, can be represented as וַיֹּולֶד בָּנִים וּבָנֹות or, in the ETCBC consonantal transliteration:
WJWLD BNJM WBNWT
The output is a string that includes the morphological encoding (for details see Part I):
W:n-!J!](H](J&WLD[ BN/JM W-B(T&N/WT:a
seq2seq and machine translation
Since both the input and the result of the morphological encoding are strings, the obvious solution for parsing texts by Machine Learning (ML) is a seq2seq model. One of the best-known applications of seq2seq modelling in the domain of text and language is machine translation. Here the input is the text in one language, the output is the translation into another language. Since the application of computation to textual analysis, people have been fascinated by the idea of the automatic translation of texts. In the first decades (roughly the 1970s to the 1990s), we see several rule-based approaches. Computer programs were instructed with an increasing number of linguistic rules that should enable them to translate a text from one language into the other. The refinement of the rules should result in an improvement of the output. However, due to the elusiveness and fuzziness of language, the results were disappointing. The application of statistical methods in the 1990s and the 2000s brought some improvement, but still the results were unsatisfying. The real breakthrough in automatic translation came through the emergence of Deep Learning in the last decade.
The difference between Machine Learning and classical programming can be visualized in the following way:
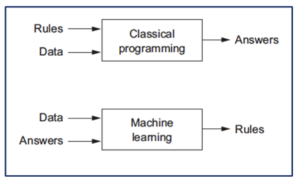
So, if one wants to have a computer program translate a Dutch text into English, in classical programming the way to go was to provide the program with a Dutch text, as well as rules about Dutch and English and a lexicon, and the intended output was an English text. In a ML approach, the input consists of texts, in this example Dutch texts (“Data”) and their English translations (“Answers”), which serve as input to train a model to translate sentences from Dutch into English. These examples are fed to the algorithm, which learns itself what the relationship is between the input and output sentences. In our case, the input and the output are not two different languages like Dutch and English, but the input is the raw text, the output is the encoded text.
seq2seq models
There are various models to make seq2seq predictions based on recurrent neural networks (RNNs). A special kind of RNN is the LSTM (Long Short-Term Memory) model. To improve the performance of the model, it is important to consider not only the preceding, but also the following context. For this reason, we used a bi-directional LSTM. Moreover, since the famous article by Ashish Vaswani et al., Attention Is All You Need, improvements have been made in seq2seq modelling because some elements in a sequence may be more relevant to make predictions than others. Attention is a mechanism that mimics cognitive attention and that increases attention to some parts of the input data and diminishes other parts. However, we still have to experiment further to make the attention mechanisms fruitful, since there are also challenges in the application of attention, as was highlighted in a succesful article by Yihe Dung et al. Attention is not all you need. Attention is also the basis for another group of models, called the transformer-based models. A transformer adopts the mechanism of self-attention, differentially weighting the significance of each part of the input data. In addition to these various models, we experimented with Beam search. This is an extension of the seq2seq models that makes multiple predictions and then selects the best output.
Hyperparameters
Finding the best way to train a model that can predict the correct output when it is fed a new input is not only a matter of experimenting with various models to see which one works best. For performance improvement we have also experimented with various tweaks of the hyperparameters. These are the variables that determine the network structure and how the network is trained and include sequence lengths, number of epochs, architecture of the model, learning rate, and drop out. Thus we found, for example, that with our parameter settings, in a sequence length of twelve words, the second word had the best result.
The challenge is to find the optimal combination of the setting for these parameters to make the best predictions. For example, if the number of times that the learning algorithm works through the entire training dataset (i.e. the number of epochs) increases, the accuracy increases as well. Likewise, a sequence of multiple words performs better than single words, hence to a certain point we can say that the longer the sequence, the better the output. However, the number of epochs and the sequence length also affect the running time. Likewise, we can experiment with the size of an LSTM layer, that is, the number of memory cells in one layer. A larger LSTM layer leads to a better performance but if the layer is increased too much, there lurks the risk that the model is “memorizing” rather than “learning” and that it becomes an echoing-pit. In this case, the network does not generalize well, because it is modeling idiosyncrasies instead of the patterns in the data. This is called overfitting. The risk of overfitting is also lurking when there is too much similarity between the training set and the test set. So finding the best settings is a matter of careful checking and experimenting.
Languages
In our project we analyzed both Hebrew and Syriac data. Since the ETCBC hosts a richly annotated linguistic database of the whole Hebrew Bible, known as the BHSA (305,000 graphic words, 426,000 functional words about 8,000 lexemes), most of the encoded data at our disposal was in Hebrew. Moreover, for Biblical Hebrew we could experiment both with vocalized and unvocalized texts. The vocalized texts contain more information and hence yield better results.
However, our aim was to apply Machine Learning to Syriac texts, for which we have a smaller corpus of encoded texts (76,800 graphic words and 12,300 functional words ; about 3,300 lexemes) that can serve as train or test set. These are mainly the texts that have been encoded in the CALAP (1999–2005) and Turgama (2006–2010) projects. Before these data could be used by the Machine Learning algorithms, they needed to be harmonized because the linguistic encoding conventions had changed considerably between the two projects to do justice, for example, to the lexeme status of pronominal suffixes attached to a noun or verb (cf. above).
With this relatively small Syriac corpus and a somewhat bigger Hebrew corpus, we decided that first the model was trained on vocalized Hebrew data. After that we trained the model in different experiments on (a) unvocalized Hebrew data; (b) Syriac data (unvocalized); (c) first Hebrew data, then Syriac data; (d) Hebrew and Syriac data together. In experiments c and d, the idea is that the relatively large amount of labeled Hebrew data helps the optimization of the model for making predictions on new Syriac input sequences. The approach in experiment c is known as Transfer Learning.
Prospects
Our practical aim is to use ML to accelerate the morphological encoding of the vast Syriac corpus. The next step will be to apply the models that have been developed in this project to the Peshitta. Since we currently reach an accuracy of about 85%, manual correction is still needed. Increasing the size of the encoded corpus will in turn help train the algorithms and result in better performance. At a methodological level, the workflow and the fine-tuning of the parameters will support future projects. Another area that we want to explore further is the relation between linguistic information and the language models used. Will the transfer learning application mentioned at the end of the preceding section help to discover commonalities in Hebrew and Syriac? Will this be applicable for other situations of multi-lingual corpora? Such questions deserve further exploration, but they are beyond the scope of the current contribution.
Reference:
Code and data on github: https://github.com/ETCBC/ssi_morphology
