This past January my Bar-Ilan University colleague, the computational linguist Moshe Koppel and I launched the Tiberias Stylistic Classifier for the Hebrew Bible (https://tiberias.dicta.org.il/#/ ). Tiberias marshals cutting edge advances in the field of machine learning and computational linguistics to empower users to easily conduct their own experiments analyzing and classifying the texts of the Hebrew Bible through the measurable features of linguistic data, and providing them with verifiable results. For its database of the Hebrew Bible, we elected to employ the ETCBC IV, as it is unparalleled in its systematic tagging of linguistic information at the word, phrase and clause level.
In this blog I would like to give a sense of the some of the contributions Tiberias can make to questions of linguistic diachronic development in the Hebrew Bible. Ever since the time of Gesenius, scholars have sought to ground their determinations of linguistic dating of the biblical texts on data that is solid. The study of language change, it was believed, is best based on the comparison of pairs of features that can be contrasted as early and late. Ideally the investigator seeks a set of at least two contrasting phenomena, one early and one late. When item A in a text corpus corresponds in meaning or function to item B in another text corpus the evidence is suggestive of language development. Scholars recognize, of course, that not all linguistic development produces contrasting features. Thus, if a term appears exclusively or nearly so in pre-exilic books that feature classical biblical Hebrew (CBH), and not at all in post-exilic books that feature late biblical Hebrew (LBH), that feature may rightly be considered a feature of CBH. In reality, however, the linguistic development of biblical Hebrew is actually manifested in literally thousands of features that do not align in neat, paired contrasts. If Hebraists have focused on contrasting pairs and on wide disparities of frequency of appearance, it is not because these are the only developments from CBH to LBH. It is because these are the features that can be documented easily and reliably. What characterizes these data is that they are stark. They are, to speak metaphorically, the brightest stars in the sky, and thus easy to see and to count. But language, and language development consists of myriad subtleties that are far harder to measure.
The capacities to easily calculate the frequencies of all linguistic features in two or more text corpora and to determine their relative significance are now available with the launch of the Tiberias. Tiberias sets to the task of building the best linguistic profiles it can of the two text classes. Through continuous internal testing it refines the models until it defines profiles of each text class that maximize its capacity to distinguish between the two text classes, and to properly classify the constituent chapters found in both text classes.
Let’s say that I create two text classes. One, composed of the books of the Former Prophets, I call CBH narrative. And one, composed of Ezra, Nehemiah, Esther, Daniel and the non-synoptic portions of Chronicles, I call LBH narrative. Through its machine learning algorithms, Tiberias analyzes the two text classes and determines that it can successfully categorize any chapter in the two text classes with 93% accuracy. Many users will not have the capacity to judge for themselves the validity of Tiberias’ statistical models, nor of the algorithms it employs from the fields of computational linguistics. But the validity of the data produced by Tiberias is not predicated on a leap of faith in the competence of its programmers. Even users ignorant of statistics and computational linguistics can check this.
Tiberias produces a report of the 500 or so features that contributed to these models. To give an example of the type of data Tiberias produces, here are the top five most significant features that distinguish between CBH narrative and LBH narrative (click to enlarge):
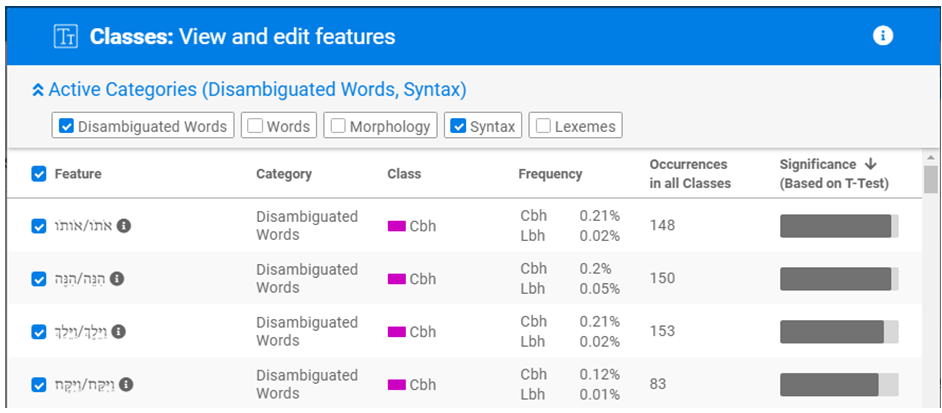
But Tiberias can not only distinguish between two text classes. Tiberias can classify a test-text as well, as more similar to one text class or the other. Gen 24 is a text that has been the subject of some discussion concerning its linguistic profile. Tiberias unequivocally classifies this chapter as resembling the profile of CBH narrative (click to enlarge)::

This screen shot captures the top nine features that contribute to this classification. Although there are many scholars who maintain that this chapter is an exemplar of CBH, they tend to point to the data achieved by conventional methods, that is the presence in the chapter of linguistic features that are typical of CBH and have a paired contrasting feature that appears in LBH. Tiberias is able to add a wealth of data to arrive at a similar conclusion. Even without the aid of linguistic contrast, Tiberias is able to point to reams of data that show that Gen 24 possesses many features which may appear in both CBH and LBH narrative, but which are more prevalent in the CBH corpus.
With these capacities, Tiberias ushers in a new tool and a new era in the study of linguistic dating of the biblical texts. It promises to similarly revolutionize our understanding of the linguistic profiles of various text classes, such as the relationship between First Isaiah and Deutero-Isaiah, so-called Priestly and non-Priestly writings and much more.
