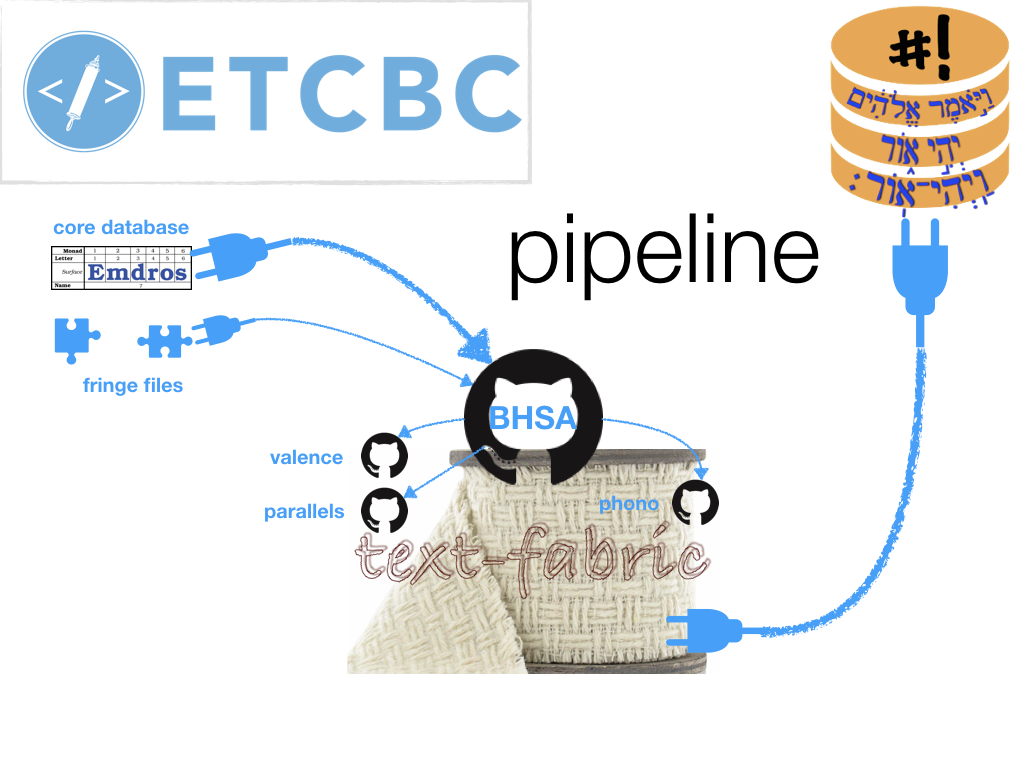
Pipeline from ETCBC to Text-Fabric
The research data developed at the ETCBC is live data. The researchers at the ETCBC continuously develop new (theoretical) insights about the research data of the Hebrew Bible and other ancient corpora (e.g. inscriptions from Qumran), review encoding mistakes, and perhaps after a good discussion: correct those mistakes. The produce of that research then is added to the server, which is based at the VU in Amsterdam. Although ETCBC’s goal is to expose the most updated version of the data to the researchers and public outside the confines of ETCBC’s secured server, until November 2017 this was not possible.
There were two worlds (small ones if you’d like), so to speak. World one being ETCBC’s server. World two consisting of ETCBC’s public data sources: the website SHEBANQ and downloadable python3 package Text-Fabric. Around the same time last year the ETCBC officially decided to do its work in the Open Science way as much as possible, but there you have these two worlds. One full of live data (the server), the other one full of data and potential to aid in enriching ETCBC’s core research data, methods and features (yes, I’m talking about Text-Fabric). Leaving out the technical issues in relation to updating SHEBANQ for now, the challenge was to offer Text-Fabric users data that is synchronised with ETCBC’s server data.
In order to frequently refuel Text-Fabric, Dirk Roorda programmed an easy to handle pipeline ‘TF from ETCBC’ (go check it out on Github) in the form of a Jupyter notebook. The pipeline produces fixed versions of all the ETCBC data named after the year in which they were produced: `2016`, `2017`, `2025`, etc. The use of fixed data versions is advisable for example if you are building statistical models on Text-Fabric datasets. The `c` version is the continuous version and thus receives the frequent updates. The ETCBC members who have access to the server can run the pipeline from any computer that has python3, Text-Fabric and Jupyter notebooks installed on it.
For those interested in the more technical side of how to refuel TF with fresh ETCBC data, these are the steps to take:
- `git pull` `bhsa`, `phono`, `parallels`, `valence` and `pipeline` the Github repositories for the most current versions of the data and software
- Log in to the ETCBC server with USERNAME
- In the server, go to the folder: tf_data_pipeline
- Run script: `sh getdata.sh` from the terminal
- Go to local folder: cd ~/github/etcbc/bhsa/source, from there:
- Run in the terminal: `scp -r USERNAME:tf_data_pipeline/data .`
- Then run in the source folder: `mv data _temp`
- Run the pipeline `tfFromEtcbc.ipynb`
- Then consolidate the `_temp` to the `c` version in the same notebook
- Check if the features in `_temp` load properly in a random notebook
- Go to: `cd ~/GitHub/etcbc/REPO`
- `git add –all .`
- `git commit “pipeline tfFromEtcbc has run”`
- `git push origin master`
- Time to celebrate, you’ve just run the pipeline

Just to fill in what Christiaan wisely left out: there is also a pipeline after this: from the data in the repos to data for SHEBANQ on the DANS/KNAW server. After that, it only takes logging in on the KNAW server and running an update script to see the new data on SHEBANQ.